

本段文字节选自北京市作协副主席乔叶先生的「烟火人间」《看云记》,发表于2023年10月17日的光明日报。…


2、核心知识点考察
2.1 理论基础与模型架构
大模型面试中的理论基础考察是评估候选人技术根基的重要环节,涉及深度学习、自然语言处理、计算机视觉等多个领域的核心概念。2025年的面试更加注重候选人对基础理论的深刻理解和灵活应用能力,而非简单记忆概念。
〖Transformer架构深挖〗作为几乎所有主流大模型的基石,Transformer架构的每一个组件都可能成为深入考察的对象。自注意力机制(Self-Attention)的计算复杂度及其优化变体(如线性注意力、稀疏注意力)是高频考点。面试官通常会要求候选人手写注意力计算公式,并解释如何将O(n²)的计算复杂度优化至O(nlogn)。位置编码(Positional Encoding)也是一个重要考点,尤其是旋转位置编码(RoPE)及其改进版本(如NTK-aware RoPE)的原理和实现方式。
〖预训练范式演进〗除了掌握自回归(GPT系列)和自编码(BERT系列)两种主流预训练方式外,候选人还需要了解最新的预训练创新,如GLM的混合掩码策略、T5的编码器-解码器框架等。面试中经常出现"为什么自回归成为最主流的预训练方法"这类问题,旨在考察候选人对不同预训练范式优劣的理解。
〖模型架构变体与优化〗2025年面试中,对模型架构变体的考察已经从单纯的原理理解转向性能与效率的平衡分析。候选人需要掌握多种注意力机制变体(如MHA、GQA、MQA)的适用场景和优缺点。Flash Attention的底层原理及其如何利用GPU SRAM提升计算效率也是常见考点。
2.2 微调技术与优化策略
大模型微调技术是将通用基础模型适配到特定领域或任务的关键手段,2025年面试中对这一部分的考察呈现出越来越细致的趋势。候选人不仅需要了解各种微调方法的原理,还需要展示在实际项目中应用这些技术的经验。
〖参数高效微调(PEFT)〗LoRA(Low-Rank Adaptation)及其量化版本QLoRA几乎是所有大模型岗位面试的必考内容。候选人需要解释LoRA的数学原理(W+BAx),说明为什么低秩分解能够有效近似全参数微调,以及如何初始化A和B矩阵。面试官可能会追问LoRA在不同模型结构(如Self-Attention和FFN层)上的应用差异,以及如何设置rank参数来平衡效果和效率。
〖强化学习人类反馈(RLHF)〗作为对齐大模型与人类偏好的重要手段,RLHF的考察重点包括PPO(Proximal Policy Optimization)和DPO(Direct Preference Optimization)算法的原理比较和实现细节。候选人可能需要手写RLHF的目标函数,并解释其中每一项的物理意义。高级岗位面试还可能涉及RLHF训练中的稳定性挑战和解决方案,如奖励黑客(Reward Hacking)问题的应对策略。
〖模型压缩与加速〗模型量化(Quantization)是面试中的高频话题,候选人需要掌握多种量化技术(如GPTQ、AWQ、GGUF)的原理和适用场景。面试官可能会考察候选人对不同精度(W4A16、W8A8)量化带来的精度损失-速度提升权衡问题的理解。知识蒸馏(Knowledge Distillation)也是常见考点,尤其是如何设计蒸馏损失函数以及如何选择教师-学生模型策略。
2.3 分布式训练与推理优化
大规模分布式训练和高效推理部署是大模型技术栈中工程性最强的环节,也是区分研究型人才和工程型人才的关键维度。2025年面试中,这一部分的考察更加注重候选人的实战经验和系统级思维。
〖分布式训练策略〗数据并行(DDP)、模型并行(Tensor Parallelism、Pipeline Parallelism)和序列并行(Sequence Parallelism)的原理及其混合使用(3D并行)是核心考点。候选人需要解释不同并行策略的通信开销和计算效率差异,以及如何根据硬件环境选择最优并行方案。DeepSpeed的Zero优化器(尤其是Stage 3)的实现原理和适用场景也是常见问题。
〖推理优化技术〗KV Cache机制及其内存优化几乎是所有大模型面试的必问题目。候选人需要解释KV Cache如何减少重复计算,以及它带来的内存挑战和解决方案(如PagedAttention)。面试官还可能考察各种推理框架(如vLLM、TensorRT-LLM)的底层原理和性能对比。高级岗位面试可能涉及推理服务化的设计,包括批处理(Batching)、动态批处理(Dynamic Batching)和连续批处理(Continuous Batching)的实现策略。
〖长上下文处理〗随着模型上下文窗口的不断扩大(从4K到1M+),长上下文处理能力成为面试的重要考察点。候选人需要掌握多种长上下文优化技术,如RingAttention、滑动窗口注意力、层次化注意力等。面试官可能会要求候选人分析不同长上下文处理技术的计算复杂度和内存占用特点,以及它们在具体场景中的应用选择。
2.4 多模态与前沿技术
随着多模态大模型的快速发展,2025年面试中对多模态技术的考察已经从概念理解转向实现细节。候选人需要展示对多模态融合机制、对齐技术和应用场景的深入理解。
〖多模态融合机制〗视觉-语言模型(VLM)的融合方式是面试考察重点,候选人需要掌握多种融合策略(浅对齐、深融合、专家增强)的原理和优缺点。例如,BLIP2的Q-Former设计原理和CogVLM的视觉专家机制都是高频考点。面试官可能会要求候选人对比分析不同多模态模型(如LLaVA、MiniGPT、CogVLM)的架构差异和适用场景。
〖跨模态对齐技术〗基于对比学习的跨模态对齐(如CLIP)几乎是多模态岗位面试的必考内容。候选人需要解释对比学习如何拉近相关图文对的表示距离,以及如何设计负样本策略。面试官还可能考察更先进的对齐技术,如基于生成式的对齐(CoCa)和基于指令微调的对齐(InstructBLIP)。
〖前沿技术热点〗2025年面试中,对前沿技术的考察比例显著增加。自主智能体(Autonomous Agents)的相关技术(如ReAct框架、思维树)成为新热点。检索增强生成(RAG)的架构设计和优化策略也是常见考点。面试官还可能询问候选人对下一代大模型技术(如混合专家模型MoE、脉冲神经网络SNN、量子计算辅助训练)的看法和理解。
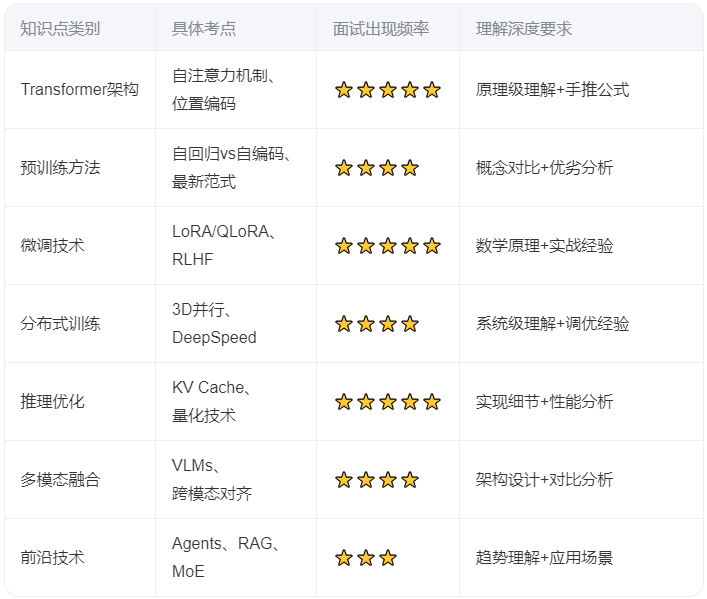 ↑表:大模型面试核心知识点及重要程度↑
↑表:大模型面试核心知识点及重要程度↑
